Introducing my rust-llama.cpp fork

Have you been looking for an easy way to use large language models (LLMs) within the Rust ecosystem so that you don’t have to leave the warm embrace of Rust’s borrow checker? Well then, do I have a fork for you!
[Editors note (Jan 2025): I’ve since abandoned this project in favor of my own set of Rust bindings called woolyrust and this fork of an existing project is no longer maintained by me.]
Background
Georgi Gerganov’s llama.cpp project has continued to progress at insane speeds, powering a huge number of open-source projects due to the ease at which you can link it’s C++ code into other projects.
Due to the breakneck pace, it’s not a sustainable idea to rewrite its functionality in Rust. So if you want to use ‘GGUF’ LLM neural networks for text inference from within Rust, the easiest and sanest path is to call the C++ library using Rust’s Foreign Function Interface features.
There are multiple ways to achieve this which basically boil down to high-level or low-level wrapper creation. A common tool to accomplish this is bindgen. Using bindgen, it becomes possible to automatically generate FFI wrappers for C/C++ code by simply writing a build.rs file to control the process. In this build.rs file, you can choose to scan the C/C++ header files and automatically create wrappers for everything it finds, all while customizing what to ignore. This works well for C, but it gets tricky with C++ because anything related to templates is unsupported. Wrapping just the plain C/C++ functions would leave you with a ’low-level’ binding, anyway.
I wanted the convenience of a higher level binding, so I looked at the listed rust-llama.cpp wrappers in the llama.cpp README file. Text inference only worked when short-circuiting the token count to obscene numbers due to memory allocation errors. The embedding functions had no chance of working because it never updated the Rust Vector’s size. All around, it looked like it was a rough port from the Go wrappers mentioned in the README file and relatively little evidence that it was actually used for anything real.
After investigating what I’d need to do to fix things up and implement features I wanted, it looked like I was going to have to invest a fair amount of time into this. For that reason, I decided to fork the repo instead of submit PR after PR. This would also mean I wouldn’t risk having features I wanted get turned down.
For this reason, my own high-level Rust wrapper fork was born: https://github.com/tbogdala/rust-llama.cpp
Feature Highlights
You can see the README file for the running list of changes, but I want to call attention to these specifically:
- More up-to-date llama.cpp pinned as a git submodule.
- Not just a more up-to-date pinned submodule, but reworked the
binding.cppcode to look similar to llama.cpp’s ownmainexample (themainexecutable that project builds for the command line). - Integration tests for basic feature coverage! (They double as examples)
- Added
cudaandmetalfeatures to the library for hardware accelerated builds. - Silenced llama.cpp output by adding a
logfilefeature to the library and have all the output directed there instead. If the feature isn’t enabled, then the llama.cpp output is dropped. Note: some GGML spam still exists at publication time. - In-memory prompt caching support so that repeat requests with the exact same prompt do not have to ingest the prompt again. This is a huge speed-up in cases where you’re running a model that is not fully offloaded to the GPU.
- Added support for GBNF Grammars so that output of the LLM can be constrained to a known format.
Admittedly, the last two features listed are possible largely due to the binding.cpp rework to use llama.cpp’s included sampler functions. And the hack used to get the metal feature working for hardware acceleration on Apple silicon came from Rustformers llm repository.
And of course, there are a few memory management related fixes like freeing models properly so you can switch them out at runtime as well as other miscellaneous fixes like actually getting the embeddings related functions working.
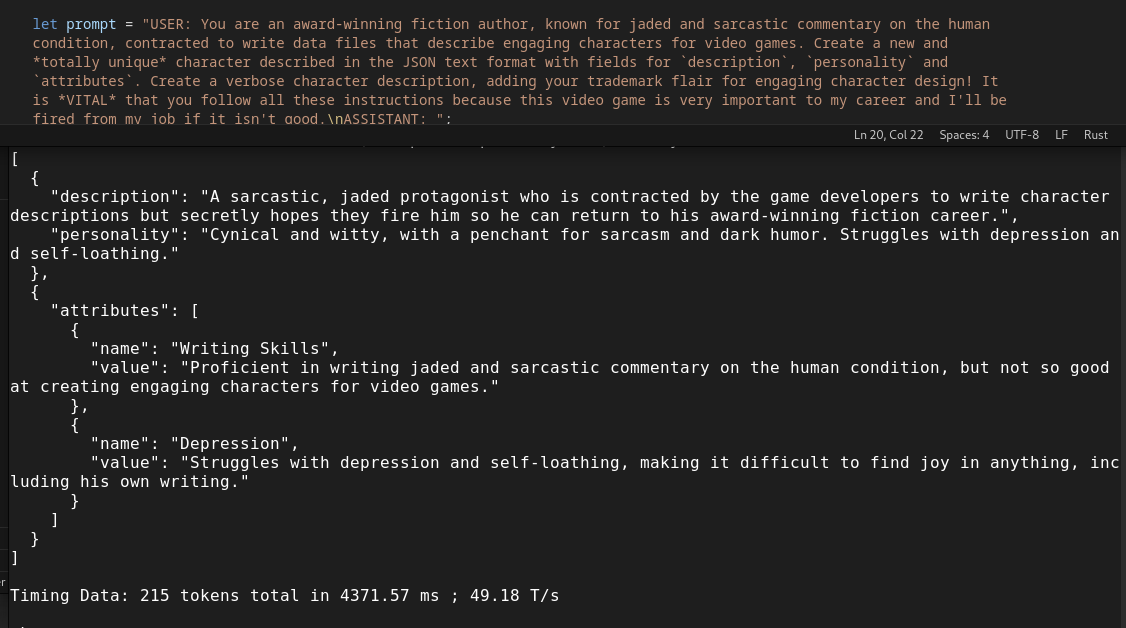
As an example of what’s possible, I had some fun with the grammar integration test and had it generate JSON for video game character descriptions. This was the first output Airoboros-L2-13B Q8_0 gave me:
How To Use The Wrappers In A New Project
All of the integration tests show how easy it can be to get results, but to be more helpful to newer rustaceans, here is a basic rundown:
Create A New App With Cargo
To create the shell of the project, use this cargo command:
cargo new hello_rusty_llama
It will tell you it’s creating a binary application.
Add The Rust-llama.cpp Dependency
My rust-llama.cpp fork is added by git reference. When you do this in a rust project, it pins the build to that specific git commit so that the build remains reproducible.
cd hello_rusty_llama
cargo add --git https://github.com/tbogdala/rust-llama.cpp llama_cpp_rs
That automatically adds the project to your dependency list in the Cargo.toml file. At this point, you should be able to execute cargo build and get a compiled “Hello, world!” output with cargo run, but we want our own locally sourced and freshly cooked text!
Download A Model
To keep things dead simple, we’re going to use a ‘old’ model: Airoboros-L2-7B-2.2.1. This is also considered a ‘small’ model, but despite that, you’ll need 8 GB of VRAM on your graphics card to run it completely accelerated. If you have less, you can run it completely - or partially - on the CPU. In the project directory, use wget to download the model, or download it by another means and move it there.
wget https://huggingface.co/TheBloke/airoboros-l2-7B-2.2.1-GGUF/resolve/main/airoboros-l2-7b-2.2.1.Q4_K_S.gguf
Write Some Code!
Finally the fun part, right?! Open up the src/main.rs file in your editor of choice and paste in the following block. It looks long but that’s just because I commented it heavily for illustration purposes.
use llama_cpp_rs::{
options::{ModelOptions, PredictOptions},
LLama,
};
fn main() {
// setup the parameters for loading the large language model file
let model_params = ModelOptions {
// the airoboros 7b model reference in this example can handle
// a context size of 4096, but more VRAM constrained machines
// might not be able to cope. Smaller context means less VRAM
// used, and we won't need this much for this example.
context_size: 2048,
// this determines how many of the 'layers' in the LLM get sent
// to the GPU for processing. specifying a large number just
// ensures all layers are offloaded. if you want to run on the
// CPU, comment this parameter out or set to 0.
n_gpu_layers: 9999,
..Default::default()
};
// load the model we downloaded with the above parameters. it will need
// to be `mut` because running Predict can update internal cached data.
let llama_filepath_str = "airoboros-l2-7b-2.2.1.Q4_K_S.gguf".to_string();
let mut llm_model = match LLama::new(llama_filepath_str, &model_params) {
Ok(m) => m,
Err(err) => panic!("Failed to load model: {err}"),
};
// setup the parameters that control the text prediction. only some
// of the possibilities are shown here.
let predict_options = PredictOptions {
// predict at most 256 tokens, which will hard stop the prediction
// at that point if the model doesn't finish earlier.
tokens: 256,
// this is how big the 'prompt' chunks should be for processing.
// if using only CPU, you may wish to set this much lower, to
// something like 8.
batch: 512,
// the following three options are 'sampler' settings to control
// how the text is predicted. play with the possibilities here...
temperature: 1.3,
min_p: 0.05,
penalty: 1.03,
// we define our callback with a closure and just have it print
// the generated tokens to stdout.
token_callback: Some(std::sync::Arc::new(move |token| {
print!("{}", token);
let _ = std::io::Write::flush(&mut std::io::stdout());
true // returning true means text prediction should continue
})),
..Default::default()
};
// this is the 'prompt' to send the LLM that is basically telling it
// what to write. different models have different formats and this
// is the format for Airoboros 2.2.1.
let prompt = "A chat\n\
USER: Write the start to the next movie collaboration between\
Quentin Tarantino and Robert Rodriguez.\n\
ASSISTANT:";
// finally, call predict() to generate the text. the callback in
// predict_options will get each token as it happens, but the final
// result will be in the (String, LLamaPredictTimings) tuple of
// the Result object returned.
let _result = llm_model.predict(prompt.to_string(), &predict_options);
}
The flow of the code should be well explained by the comments. To see it run accelerated on your GPU, just run it with cargo:
cargo run --features "llama_cpp_rs/cuda"
Note: If you’re running on Apple silicon, the feature you need is actually "llama_cpp_rs/metal". And if you’re running on CPU only, you can omit the features parameter all together and just use cargo run.
What Next?
That’s basically how easy it is to start with the rust-llama.cpp wrapper. You can play with some PredictOptions fields to change the samplers. You could set the prompt_cache_in_memory field to true and then call predict multiple times with the same prompt but with different sampler settings. You could pull one of the sample grammars from llama.cpp into a string and then the PredictOptions’s grammar string to that to constrain it’s output. You could import reqwest, pull content from the web, push it into a prompt and ask the LLM to summarize it … The world’s your oyster.
Hell, if you’re ambitious enough, you can write your own terminal UI chat application and create a character based on Flynn from the movie ‘Tron’ and chat with him for game development advice … but more on that later …